

Imagine two factories - one in London, one in Manchester. Each has a bell which rings at exactly midday to mark the end of the morning shift. Empirically, it is true that every time the bell in Manchester sounds, the workers in London will knock off for lunch. Obviously, the first is not the cause of the second. For philosophers though, the question is how do we actually know this? What is the nature of causality and how can it be observed? In their incredibly entertaining tour of mid 20th century philosophy, John Eidinow and David Edmonds relate how this seemingly frivolous question occupied the minds of thinkers such as Bertrand Russell and Richard Braithwaite in the Cambridge of the 1940's. At first glance, these arguments might seem arcane and esoteric, yet today they are still occupying researchers in the cutting-edge field of Causal AI.
This is because, whilst causality may seem obvious from a common-sense point of view, the actual mechanics can prove rather elusive. Causality seems to only manifest itself as a poltergeist, it is something that we infer from effects rather than observe directly. This is a problem that was addressed by the Scottish philosopher David Hume in the 18th century. In his book on Causal Inference and Discovery in Python Aleksander Molak summarises Hume's' position as follows:
- We only observe how the movement or appearance of Object A precedes the movement or appearance of Object B
- If we experience such a succession a sufficient number of times, we’ll develop a feeling of expectation
- This feeling of expectation is the essence of our concept of causality.
In this reading therefore, cause is not a phenomenon that we can see or experience at first hand. It is a cognitive construct that we apply on the basis of repeated experiences.
The question of causation is a fundamental concern in all kinds of observability scenarios - not just in computing but in a wide range of domains such as engineering, transport, health and many others. However, if humans struggle to define a formal system of logic for establishing cause and effect, then how can we model it in computer systems? How, from the vast mass of individual data points ingested into an observability system, can a computer program construct deterministic relationships and state, categorically, that event A and event B have a causal relationship? The question becomes even more vexed in contemporary computer architectures where code is not confined to a single executable but is distributed across decoupled components.
The revolution in AI and the massive growth of the observability market have converged to create a fertile space for companies aiming to provide a solution to this problem. One of the early movers in this space is Causely, a company which recently raised $8.8m in seed funding to "deliver the IT industry's first causal AI platform". Before delving into Causely as a product, it might be worth taking a detour around the problem domain to gain some theoretical context.
AI is a term which is being used ever more frequently in product marketing. Often, what this boils down to is the ability to make associations and correlations on the basis of machine learning. Whilst this can produce incredibly useful results in many contexts, it does have its limitations. For purposes such as root cause analysis, these limitations become especially problematic.
If you have ever used a tool such as Dall-E, you cannot fail to be impressed at its ability to turn simple text commands into compelling images. The example below, however, shows that whilst Dall-E can generate a well-formed image it has not "understood" the sense of the request. It has correctly associated words with images but the assembled result seems to reflect the patterns of the training data rather than an intelligent adaption to the request.

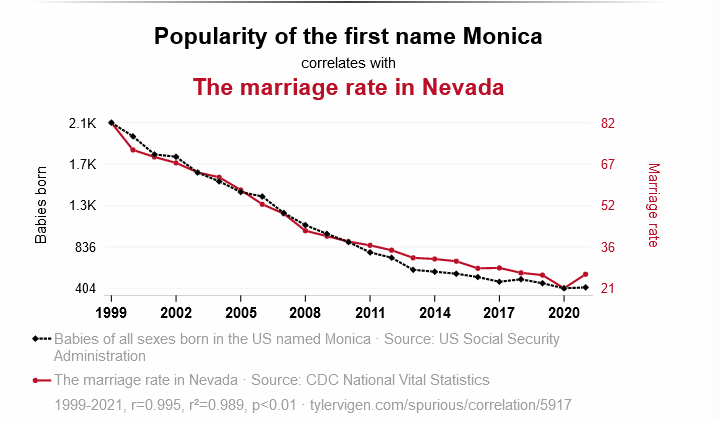
Correlation is generally regarded to be prone to two major weaknesses. The first is that correlations, even though they may be statistically strong, can often be arbitrary. A classic example is that increases in incidents of drowning can be very strongly correlated with increases in the consumption of ice cream. Whilst we could speculate that increased sugar intake from ice cream consumption may have some undesirable metabolic effects and result in swimmers getting into difficulties, this is not a convincing explanation. The common factor underlying both of these trends is increases in average temperature. As the weather gets hotter, people are more likely to go swimming and therefore more drownings are likely to occur. Some people argue that such misleading associations are rare in the real world. The example below however, is just one of a whole menagerie of spurious - and highly entertaining associations - curated on the Tyler Given web site.
The second major limitation of correlations is that they do not necessarily reveal the direction of a relationship. There is, for example, a correlation between depression and low Vitamin D consumption. What is not clear, however, is whether depression causes low Vitamin D consumption or vice versa. One of the most infamous abuses of this ambiguity over the direction of causality was framed by the statistician Ronald Fisher, in his notorious paper Cigarettes, Cancer and Statistics. In the 1950's a number of statisticians used Bayesian methods to produce a compelling case for the link between smoking and lung cancer. Fisher who was both a heavy smoker as well as a paid consultant to the tobacco industry, launched a vigorous and sustained counter-attack where he questioned whether it was actually cancer that caused smoking.

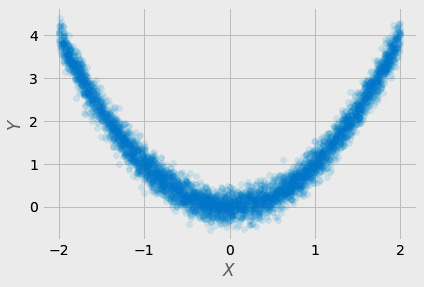
Interestingly, as the diagram below shows, it is also possible to have cause without statistical correlation. There are interesting real-life examples of these kinds of V-shaped relationships between two variables. For example, the effect of changes in temperature on the metabolism of animals. In this case, the value of 0 represents an optimal baseline. A deviation from this baseline - either positive or negative direction will result in the same upward curve of physiological stress. In some statistical methods these two trends will cancel each other out so that the correlation is low or zero.
There are a number of approaches in the field of Causal AI which can help to overcome the limitations of the correlation approach. One of these is the use of expert knowledge - a term covering various types of knowledge that can help define or disambiguate causal relations between two or more variables. Depending on the context, expert knowledge might refer to many different sources including randomized controlled trials, historic evidence, empirical data or even the laws of physics.
The seminal paper High Speed and Robust Event Correlation by Shaula Yemini et al probably represents a classic example of the expert approach. The paper dates back to 1996 but its analysis seems to be as relevant as ever. Its main thesis revolves around how an apparently tiny fault within one component unfolds a kind of butterfly effect within a larger distributed network system. It highlights how a statistically insignificant fault in a network interface results in network packets being dropped. This, in turn, leads to a throttling of the TCP window size. This has the knock-on effect of slowing down database transactions so that locks start to occur. This then has cascading effects on all services using the database. A major disruption for end users therefore results from a 0.1% loss in the capacity of a T3 network link at several removes in the causality chain. This highlights two fundamental issues:
These findings reinforce the need for root cause analyses to be embedded in frameworks of expert knowledge. As the authors state:
"to determine which events to monitor operational staff must be familiar with the operational parameters of each managed object"
The authors of the paper define a strategy which they refer to as 'coding'. This is not coding in the sense of writing a computer program. Instead, it involves identifying all of the particular symptoms of an exception and then grouping them together to create a unique profile. This kind of fingerprinting is a powerful and performant tool for identifying patterns within streams of telemetry data and mapping them back to known causes.
Circling back to Causely, it is the application of these principles that underpins its root cause analysis capabilities. At the moment, you will need to book a demo to see the product in action. However, we can get a flavour of its functionality from videos posted on the Causely web site.
The first video we will look at covers how Causely identifies causal relationships from OpenTelemetry traces (although it also has integrations for eBPF and Istio to support service discovery). Although this does not require any instrumentation at the code level, it obviously assumes that you are collecting trace telemetry. In terms of configuration, all you need to do is export your traces to the Causely endpoint (in a real-world case, you would obviously not use the insecure TLS option).
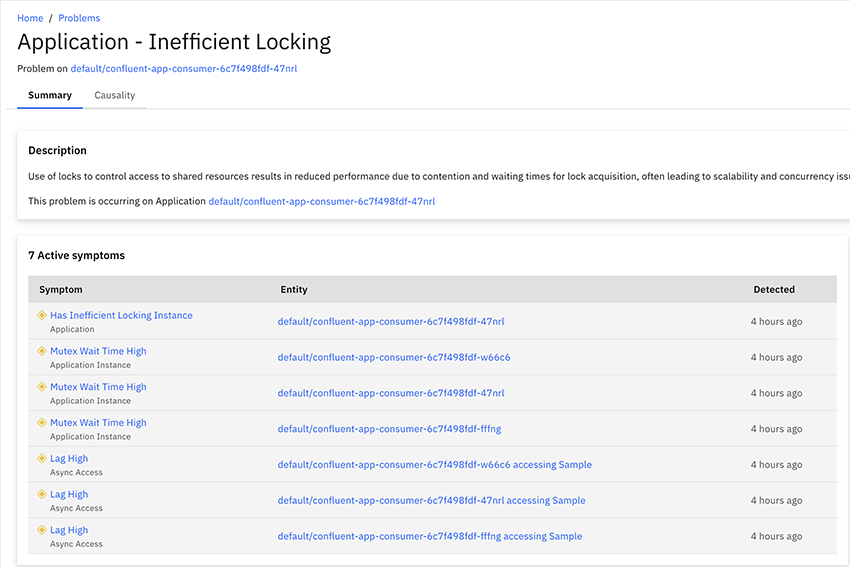
Causely can detect problem conditions from your trace data and assemble a graph of the issue - it can then correlate this with its own models to identify root causes. By taking this approach it can achieve a higher level of determinism whilst needing less raw data and less compute power. What is interesting is that Causely can use its expert knowledge to define a potential or actual problem autonomously. It can then combine this intelligence with its knowledge of the service graph to predict effects on dependent services. In the example below it has identified an Inefficient Locking issue:
We can then drill down and see the components affected by this issue:
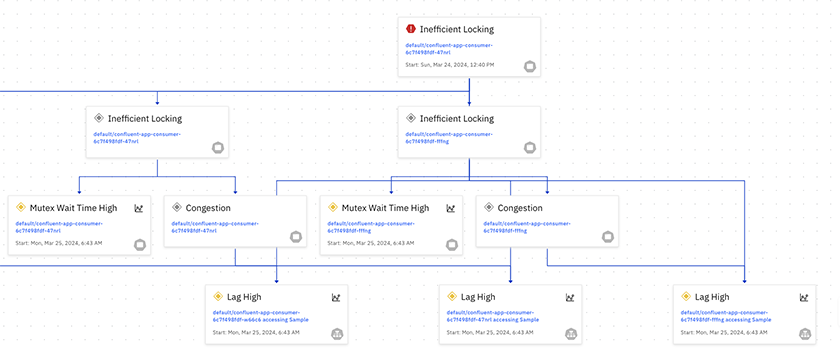
Many monitoring systems identify errors on the basis of testing binary states or predefined signals and codes - e.g. pinging an endpoint or capturing output to stderr. On the basis of these videos Causely is able to autonomously identify which values in a dataset may represent a problem state - it does not have to be 'trained' to search for predefined, thresholds or ranges. If this is the case, then this is an advanced capability absent from most other products on the market.
The second video looks at a common scenario - asynchronous failures in a distributed services system. The screenshot below depicts the architecture for a sample application:
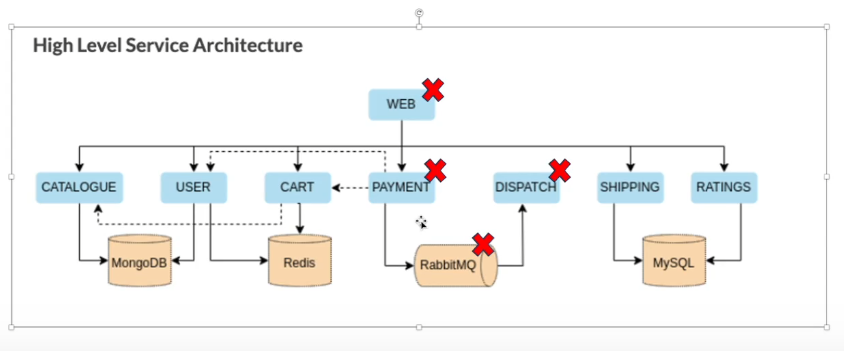
We can see that if there is a failure in the RabbitMQ service, it will cascade in multiple directions. At this point, many monitoring systems may start sending discrete streams of error messages for each of the affected services - but without linking them to a root cause. In Causely, these individual error conditions can be viewed in the Symptoms screen:
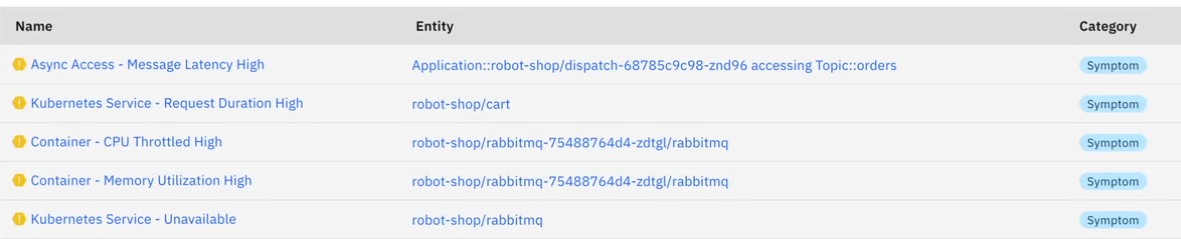
In the defects screen, Causely will display a list of error conditions which are at the root of downstream issues:
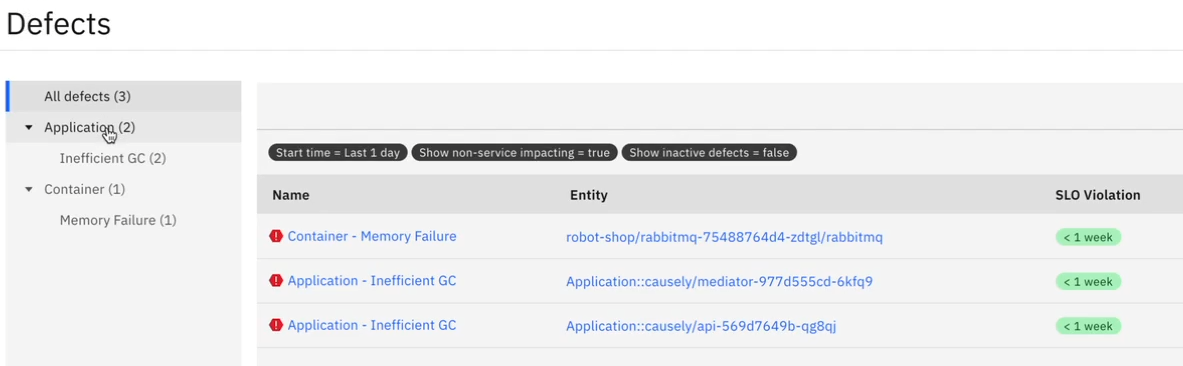
We can see here that one of our defects is a memory failure in the RabbitMQ instance. If we now click on this we can view the causality chain of affected services:
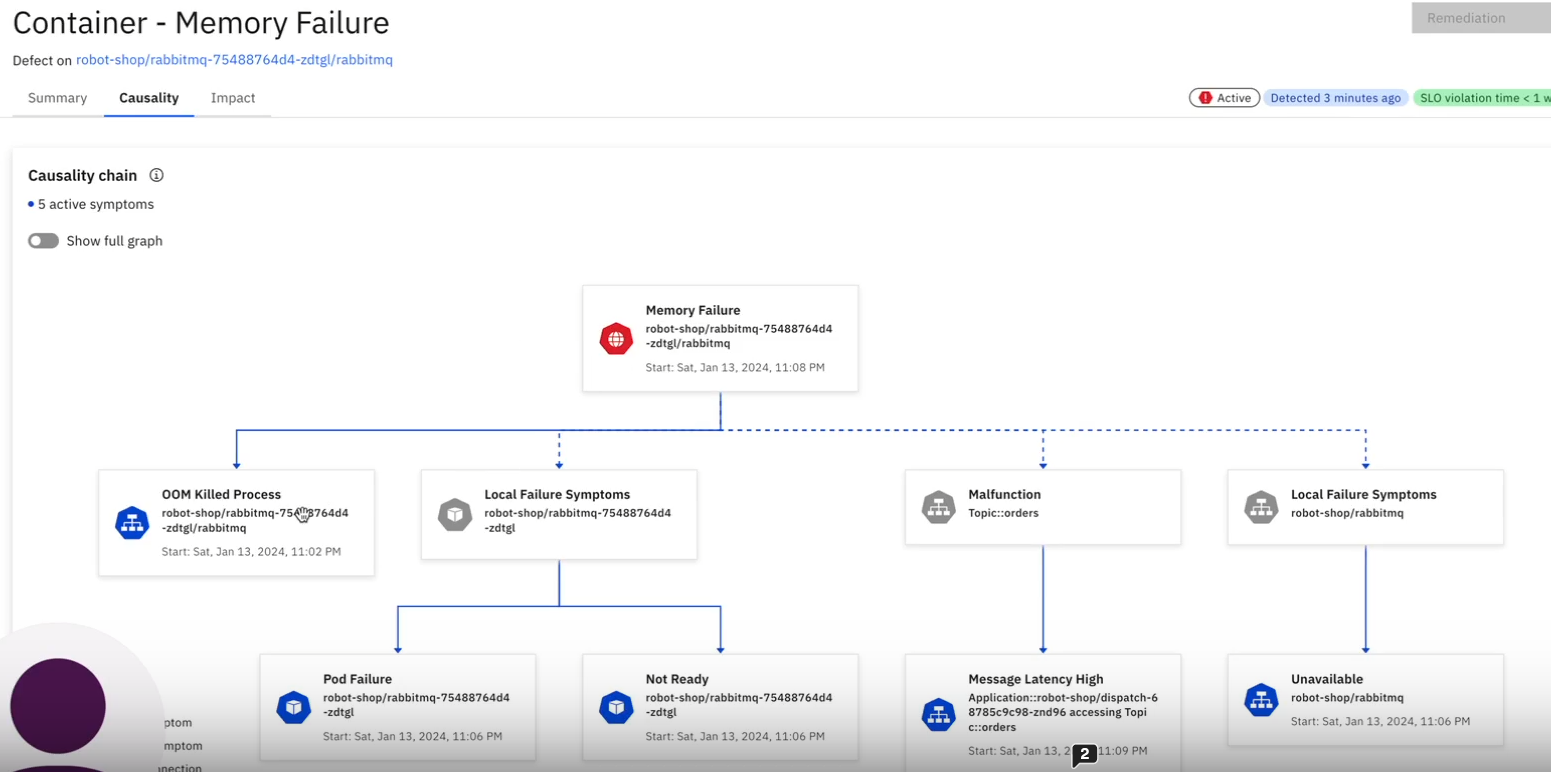
This gives great visibility of the system-wide impact of a root defect. What is also really interesting here is that Causely does not restrict itself just to displaying outages or run time errors, it is also able to identify downstream conditions such as latency issues. Another really powerful feature is Causely's ability to use its understanding of system relationships to perform what-if analysis. The screenshot below shows Causely's 'Potential Defects' screen.
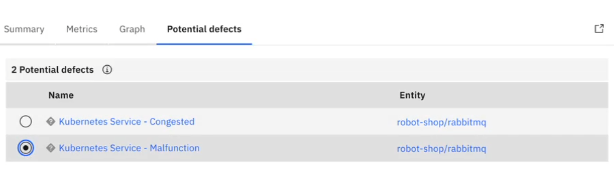
What is fascinating here is that these are potential scenarios. These are faults that have not yet happened. For the purposes of preventative maintenance though, we can now drill down and gain an understanding of the possible impacts:
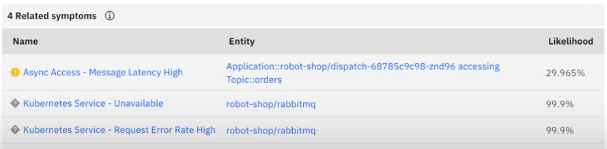
This is a useful tool for preventive maintenance, SLO management and site reliability planning.
Today's enterprise software systems can represent significant challenges when engineering teams need to tackle errors and outages. Applications tend to have more layers of abstraction, more pluralistic architectures and vastly more complex graphs. In these scenarios, failures tend to be not only more costly but also more difficult to locate. A tool that can apply expert knowledge and trace an error back through several system layers to its point of origin can be of immense value.
Causely is not intended to be a replacement for your existing observability stack. As an integration into your existing system however, it has the potential to massively reduce MTTR and enhance reliability.
I would like to express my gratitude to Andrew Mallaband for all of his help and advice in preparing this article. I would highly recommend getting in touch with him if you are looking for a guide in navigating this terrain.
If you are interested in the field of Causal Science, then the best starting point is probably The Book of Why by Judea Pearl - who is widely regarded as the leading authority in the field.
If you want to keep up with the latest news on Causal AI then I would highly recommend subscribing to the Causely newsletter.
Cigarettes, Cancer and Statistics by Ronald Fisher
High Speed and Robust Event Correlation by Shaula Alexander Yemini et al
Wittgenstein's Poker by David Edmonds and John Eidinow
Causely raises $8.8M in Seed funding Causely Press Release
Causal Inference and Discovery in Python by Aleksander Molak
Spurious Correlations by Tyler Given
Cracking the code of complex tracing data Causely web site video
Causely for asynchronous communication Causely web site video
The excellent Alex Ewerlöf blog is now back in full swing and in this latest article he turns his attention to dealing with a real SRE curveball - how to build reliability engineering for an air-gapped system. We are talking hermetically sealed - not even a maintenance window for external connectivity. This task involved a high-security military facility where installing updates meant physically handing over an archive file to a system operator.
The constraints were pretty stringent - no logs, no metrics, no traces, no remote access of any kind.This was an extreme case and, ultimately, the solutions had to be both human-centred as well as relatively low-tech. How would you address the challenge? Hit the link below to read about the solution that Alex put in place.
In the past month or so the GitHub platform suffered a number of well-documented outages which resulted in loss of service for users. In the spirit of transparency, GitHub CTO Vlad Fedorov published this article on the GitHub blog, explaining the causes of the outages and the lessons learned as well as detailing the remediations that GitHub engineers will be putting in place.
The article really brings home the challenges of orchestrating the components of a global technology infrastructure - as well as the compounding effects of working at very large scale. The investigation revealed a perfect storm of edge cases, hidden tipping points and unforeseen knock-on effects. It’s impossible not to feel for the engineers sweating in the war-rooms as the dramas unfolded - after all, watching your failover fail must be pretty gut-wrenching.

If the Observability world had a code of secrecy akin to that of the Magic Circle, then Charity Majors might be in danger of being banished to exile and ignominy. In a single slide deck, she has blown the gaff on a whole trove of insider knowledge. It is the “What they don’t teach you at Harvard Business School” of observability knowledge. Not the abstract theory or technical detail but lessons and insights from the o11y frontline.
The deck in question was used in a talk at the LeadDev event in Berlin earlier this month and its 52 slides are an illuminating distillation of observability wisdom. We actually weren’t present at the talk and only came across the deck thanks to a mention in Michael Hausenblas’s excellent olly news newsletter. However, the slides contain sufficient clues (and images of unicorns) to easily re-construct the narrative and win friends and influence people as an observability savant.

If you are an SRE, when an outage happens you will know about it pretty quick. With security breaches the picture is rather less clear as, by their nature, they are designed to go undetected. Intrusion detection therefore is often based on a mixture of tools designed to spot unusual spikes, suspicious patterns or failed logon attempts.
This article by Fatih Koç argues that one of the major difficulties involved in identifying attacks is that of correlating signals across multiple sources such as Falco, Prometheus, Kubernetes Audit Logs etc. In this article, he outlines a strategy for extracting relevant data from each of these sources and pulling it together into a single observability dashboard.

The first line of cyber defence is normally at the perimeter - preventing attackers from entering your network in the first place. The next line of defence is intrusion detection. This can often take the form of anomaly detection using a variety of heuristics.
There are also some more creative possibilities, such as the canary solution adopted by Grafana. Just as the canary in the coalmine sings to alert underground workers to the presence of toxic gases, Grafana’s canary was designed to alert them to the possible presence of intruders in their domain.

Load testing can be simple in theory but in modern distributed architectures, it involves a lot more than throwing requests at an individual service. This article on the Airbnb engineering blog looks at how the company’s engineers use the Impulse load-testing framework to handle a number of more complex requirements such as dependency mockingand managing messaging and asyncronous calls.
Unfortunately, at the moment Impulse is just an internal Airbnb framework, so you won’t be able to get your hands on it at present. At the same time, the article provides a valuable blueprint for tackling advanced, real world load testing scenarios.
It's an announcement that might have seemed unthinkable not long ago, but the porting of the revolutionary eBPF technology to Windows is now a reality. The ability to bring safe programmability to the kernel has resulted in enormous gains in fields such as security, networking and observability for Linux hosts, so applying the same principle to the Windows ecosystem is obviously an attractive proposition. It is not, though, without its own difficulties. There were a lot of hurdles to overcome and, inevitably, given the differences in OS architecture, this is not a full-fidelity replica of the Linux implementation.
This possibly foundational article by Pavel Yosifovich guides you through the steps involved in boldly going where few have gone before and creating your first eBPF program for Windows. One paragraph in the article begins with the sentence “this is where things get a bit hairy“ - for some that will likely be a challenge rather than a deterrent. This may not be cooking up nuclear fusion in your bedroom, but it does feel pretty radical.

As well as rolling out their Open AI observability solution, Elastic have also been very active within the OpenTelemetry project. C++ has a reputation for being something of a fearsome foe for observability practitioners. In this article on the Elastic blog, Haidar Braimaanie dons his protective gear and attempts to tame the beast with a soothing dose of OpenTelemetry instrumentation.
Unlike languages built in frameworks such as .NET, C++ does not have a standardized runtime environment that supports dynamic instrumentation across all platforms and compilers. C++ also uses a variety of build systems such as Makefiles and CMake, so that implementing instrumentation can be difficult and error-prone. In the article, Haidar looks at adding OpenTelemetry support to a C++ application running on Ubuntu 22.04. He also includes sample code for instrumenting the project with database spans and then observing the application in APM.
After reading this article you may want to give the C++ developer in your life a hug.

Even if you are not familiar with the name of Brendan Gregg, you are almost certainly familiar with the fruits of his labours. Brendan is the creator of the Flame Graph - one of the most important and iconic visualisations in the observability toolkit.
We featured the Flame Graph in our recent tribute to the work of UX designers in the observability arena - but you should also visit Brendans’ web site.
Brendan's latest innovation is the AI Flame Chart. This is an evolution of the original flame graph and its ambitious aim is to help reduce the vast financial and environmental costs entailed in the use of LLM’s. This means that whereas the original flame graph was focused on CPU cycles, the latest generation sets its sights on reducing GPU load. The article discusses the considerable complexities involved in mapping GPU programs back to their corresponding CPU stacks.
The names of some of the instruction sets look intimidating to the uninitiated but the basic concept of the graph is quite simple - the wider the bar, the more resource it consumes.
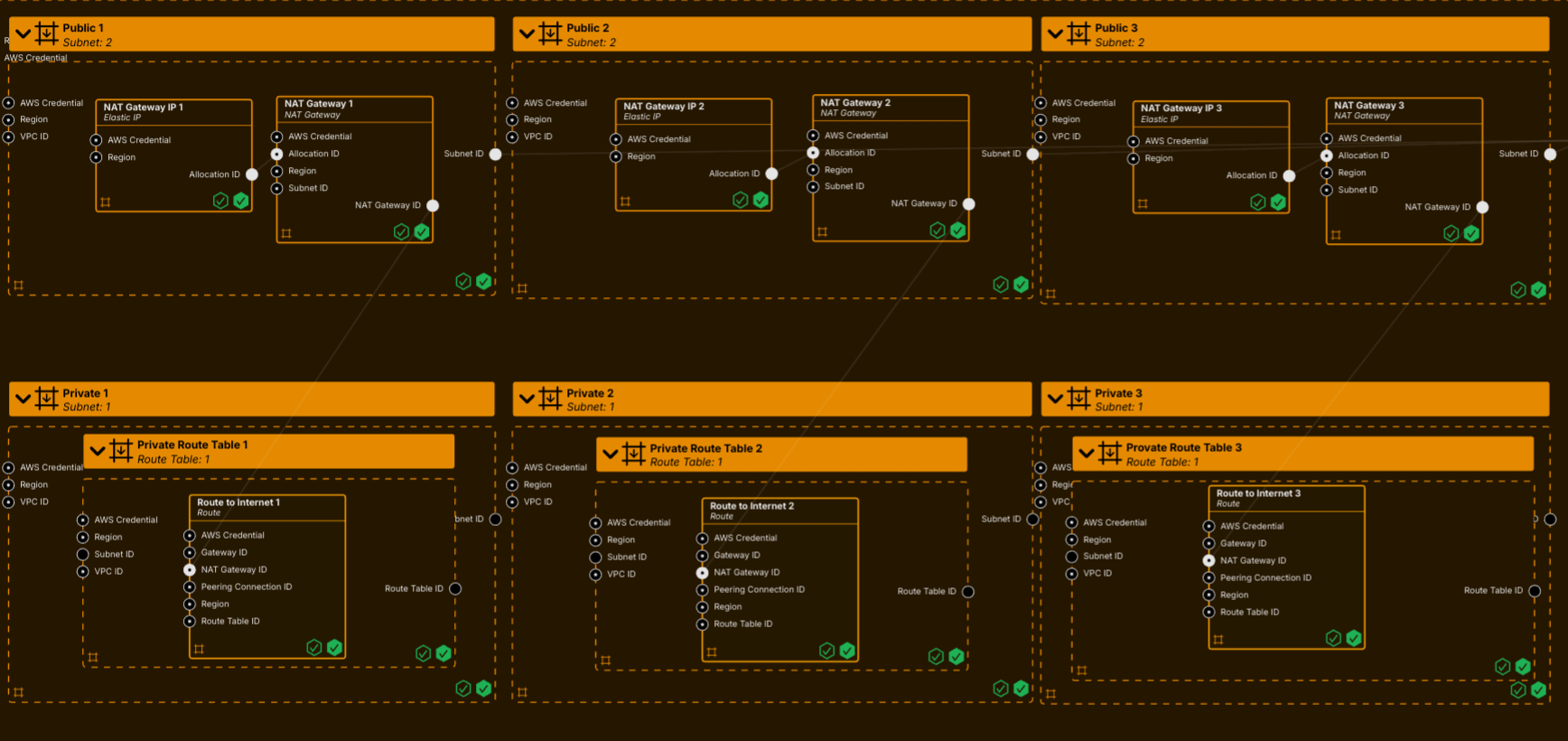
If you have ever had to grapple with a 3,000 line Helm chart to deploy your observability infrastructure, you may be forgiven for thinking that there must be a better way to do this. Whilst YAML has a certain formal elegance, its syntax struggles to express the architectures and relationships embedded in highly complex systems.
Whilst Pulumi have tackled this problem by enabling the use of high level programming languages for IaC, System Initiative are taking a fundamentally more radical approach. Their goal is nothing other than completely reinventing IaC from the ground up. The blog article for the launch of the product is an incredibly ambitious statement of intent. The terms ‘game changer’ and ‘paradigm shift’ tend to be thrown around somewhat casually, this might be a case where their usage is appropriate.
So, what are they proposing? Well, System Initiative is IaC without the code. It is a kind of digital canvas where you manipulate digital twins of your systems. Is the future here or is this the Platform Engineering equivalent of science fiction? Read the article and decide for yourself!