

Many vendors I talk to are not even sure if their product is an observability product and then still others, whose products almost certainly are observability products, don't want to market them as observability products because they think that the space is becoming saturated. We have now kind of reached a consensus on what observability does not mean - i.e. that observability is not just about the three pillars. At the same time though, there is not much consensus about what it does mean. At the empirical end of the spectrum that are those who define observability as processing telemetry and then at the more abstract end there are positions such as "observability is about being able to ask questions of your system". You can have your observability burger your way! Some of us want to know if our K8S pods are overheating, and some of us want to understand our sales pipeline. But that's actually ok. As we say, it's a big tent.
What happened?? Why did that system go down? If we want to answer that question, then we obviously need to have historical data. The problem is that modern computer systems generate huge volumes of telemetry. Since we never in know in advance which system might fail, we play safe and cover all our bases. This gives us a warm feeling, but it also means that we have the engineering problem of ingesting that data and the economic problem of paying for it. To be honest, to an extent, the engineering problem of mass ingestion has been solved. Unfortunately, the problem of querying that mountain of data so that we can quickly make sense of it, is still hard.
But it's still not really possible. Ultimately, as an SRE or a DevOps engineer, I would rather not have to figure out what went wrong. I would really like a system that would be able to help me prevent the outage in the first place. Sure, it's great that my system can alert me that a pod went down with an OOM Kill, but if I'm paying a six or seven-figure sum for a state of the art system - can't it actually figure this stuff out pre-emptively? I mean, I have fed it several petabytes of historical data - why can't it be a bit more predictive? At the moment, it turns out that this is still a hard problem.
Root cause analysis is a seductive phrase but, in practice, it is something of a chimera. Unfortunately, the mechanics of cause and effect are not always visible. Even more unfortunately, causes themselves are not always mechanical. In loosely coupled, complex and highly distributed systems, they can sometimes only be inferred. And, as a growing body of theory tells us, failures in complex systems are often not mono-causal. Maybe it is even the case that attempting to pinpoint a single cause for an error condition is a particular prejudice of human inquiry rather than a self-evidently correct approach.
Complexity is pretty much taken for granted in modern IT landscapes. It is part of the wallpaper. And then we pile one layer of complexity on top of another. Distributed services, interconnected network topologies, enterprise messaging backbones. They are designed by clever people and they do complex, high tech stuff. The terabytes of logs, metrics, traces, events etc generated by these systems don't tell a story by themselves. Turning these huge heaps of data points into meaningful analyses requires deep domain knowledge as well as heavy-duty engineering and some highly skilled UI design. The complexity of observability systems is a function of the complexity they observe.
Very few organisations actually have dedicated observability specialists - at best they may have one or more DevOps or Platform engineers that have some familiarity with some aspects of one or two observability products. Most organisations don't have staff with experience and expertise in instrumenting their systems optimally or in the best ways to filter, forward, consolidate and configure that telemetry. Traversing a wide and unfamiliar landscape without a map or a compass is not a simple endeavour.
Procuring a unified observability system is actually a considerable undertaking. Effectively, you cannot really evaluate the system without re-instrumenting some of your existing services and infrastructure. It is not easy to do this without impacting an existing environment or spinning up a new one. You will also have to coordinate across multiple teams and set up a whole variety of testing scenarios. Most organisations simply do not have the time to go through this process over and again so that they can compare vendor tools. Often this means that customers don't end up with the best tool for the job.
If you are a developer and you want to know about OOP or the principles of RESTful API's, the chances are that the canonical texts are not written by a particular vendor. More likely they are the product of collaborations by networks of subject matter experts or reflect a coalescence of academic traditions.
In the observability realm, much of the narrative-making tends to have a more vendor-led feel. Those vendors though, are often focused on the concerns of big-ticket clients. The "problems", therefore, are often stated as dealing with petabyte scale ingestion or cardinality explosions or traces with tens of thousands of spans. This results in heroic feats of engineering that captivate audiences at conferences (me included!), but it may not reflect the actual day to day concerns of many practitioners.Organisations that have adopted OpenTelemetry will not have to go through the pain of re-instrumenting their code in order to evaluate or switch to a new vendor. Equally eBPF offers the possibility of zero code instrumentation for companies running compatible workloads. And, of course, AI tooling holds out the prospect of automation to help mitigate the observability skills gap. Will this lead us to a technological nirvana of systems functioning in perfect harmony? Hopefully not, the hard problems are the best ones.
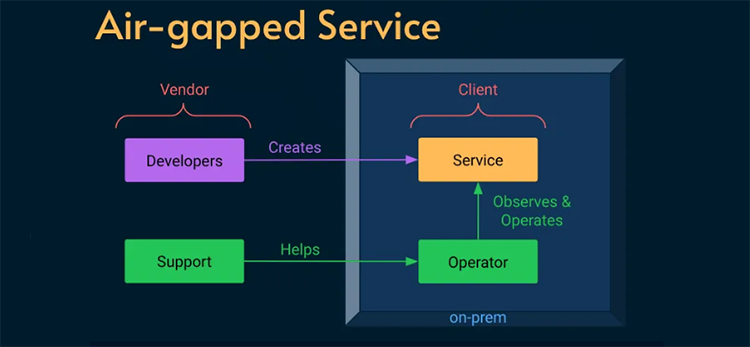
The excellent Alex Ewerlöf blog is now back in full swing and in this latest article he turns his attention to dealing with a real SRE curveball - how to build reliability engineering for an air-gapped system. We are talking hermetically sealed - not even a maintenance window for external connectivity. This task involved a high-security military facility where installing updates meant physically handing over an archive file to a system operator.
The constraints were pretty stringent - no logs, no metrics, no traces, no remote access of any kind.This was an extreme case and, ultimately, the solutions had to be both human-centred as well as relatively low-tech. How would you address the challenge? Hit the link below to read about the solution that Alex put in place.
In the past month or so the GitHub platform suffered a number of well-documented outages which resulted in loss of service for users. In the spirit of transparency, GitHub CTO Vlad Fedorov published this article on the GitHub blog, explaining the causes of the outages and the lessons learned as well as detailing the remediations that GitHub engineers will be putting in place.
The article really brings home the challenges of orchestrating the components of a global technology infrastructure - as well as the compounding effects of working at very large scale. The investigation revealed a perfect storm of edge cases, hidden tipping points and unforeseen knock-on effects. It’s impossible not to feel for the engineers sweating in the war-rooms as the dramas unfolded - after all, watching your failover fail must be pretty gut-wrenching.

If the Observability world had a code of secrecy akin to that of the Magic Circle, then Charity Majors might be in danger of being banished to exile and ignominy. In a single slide deck, she has blown the gaff on a whole trove of insider knowledge. It is the “What they don’t teach you at Harvard Business School” of observability knowledge. Not the abstract theory or technical detail but lessons and insights from the o11y frontline.
The deck in question was used in a talk at the LeadDev event in Berlin earlier this month and its 52 slides are an illuminating distillation of observability wisdom. We actually weren’t present at the talk and only came across the deck thanks to a mention in Michael Hausenblas’s excellent olly news newsletter. However, the slides contain sufficient clues (and images of unicorns) to easily re-construct the narrative and win friends and influence people as an observability savant.

If you are an SRE, when an outage happens you will know about it pretty quick. With security breaches the picture is rather less clear as, by their nature, they are designed to go undetected. Intrusion detection therefore is often based on a mixture of tools designed to spot unusual spikes, suspicious patterns or failed logon attempts.
This article by Fatih Koç argues that one of the major difficulties involved in identifying attacks is that of correlating signals across multiple sources such as Falco, Prometheus, Kubernetes Audit Logs etc. In this article, he outlines a strategy for extracting relevant data from each of these sources and pulling it together into a single observability dashboard.

The first line of cyber defence is normally at the perimeter - preventing attackers from entering your network in the first place. The next line of defence is intrusion detection. This can often take the form of anomaly detection using a variety of heuristics.
There are also some more creative possibilities, such as the canary solution adopted by Grafana. Just as the canary in the coalmine sings to alert underground workers to the presence of toxic gases, Grafana’s canary was designed to alert them to the possible presence of intruders in their domain.

Load testing can be simple in theory but in modern distributed architectures, it involves a lot more than throwing requests at an individual service. This article on the Airbnb engineering blog looks at how the company’s engineers use the Impulse load-testing framework to handle a number of more complex requirements such as dependency mockingand managing messaging and asyncronous calls.
Unfortunately, at the moment Impulse is just an internal Airbnb framework, so you won’t be able to get your hands on it at present. At the same time, the article provides a valuable blueprint for tackling advanced, real world load testing scenarios.
It's an announcement that might have seemed unthinkable not long ago, but the porting of the revolutionary eBPF technology to Windows is now a reality. The ability to bring safe programmability to the kernel has resulted in enormous gains in fields such as security, networking and observability for Linux hosts, so applying the same principle to the Windows ecosystem is obviously an attractive proposition. It is not, though, without its own difficulties. There were a lot of hurdles to overcome and, inevitably, given the differences in OS architecture, this is not a full-fidelity replica of the Linux implementation.
This possibly foundational article by Pavel Yosifovich guides you through the steps involved in boldly going where few have gone before and creating your first eBPF program for Windows. One paragraph in the article begins with the sentence “this is where things get a bit hairy“ - for some that will likely be a challenge rather than a deterrent. This may not be cooking up nuclear fusion in your bedroom, but it does feel pretty radical.

As well as rolling out their Open AI observability solution, Elastic have also been very active within the OpenTelemetry project. C++ has a reputation for being something of a fearsome foe for observability practitioners. In this article on the Elastic blog, Haidar Braimaanie dons his protective gear and attempts to tame the beast with a soothing dose of OpenTelemetry instrumentation.
Unlike languages built in frameworks such as .NET, C++ does not have a standardized runtime environment that supports dynamic instrumentation across all platforms and compilers. C++ also uses a variety of build systems such as Makefiles and CMake, so that implementing instrumentation can be difficult and error-prone. In the article, Haidar looks at adding OpenTelemetry support to a C++ application running on Ubuntu 22.04. He also includes sample code for instrumenting the project with database spans and then observing the application in APM.
After reading this article you may want to give the C++ developer in your life a hug.

Even if you are not familiar with the name of Brendan Gregg, you are almost certainly familiar with the fruits of his labours. Brendan is the creator of the Flame Graph - one of the most important and iconic visualisations in the observability toolkit.
We featured the Flame Graph in our recent tribute to the work of UX designers in the observability arena - but you should also visit Brendans’ web site.
Brendan's latest innovation is the AI Flame Chart. This is an evolution of the original flame graph and its ambitious aim is to help reduce the vast financial and environmental costs entailed in the use of LLM’s. This means that whereas the original flame graph was focused on CPU cycles, the latest generation sets its sights on reducing GPU load. The article discusses the considerable complexities involved in mapping GPU programs back to their corresponding CPU stacks.
The names of some of the instruction sets look intimidating to the uninitiated but the basic concept of the graph is quite simple - the wider the bar, the more resource it consumes.
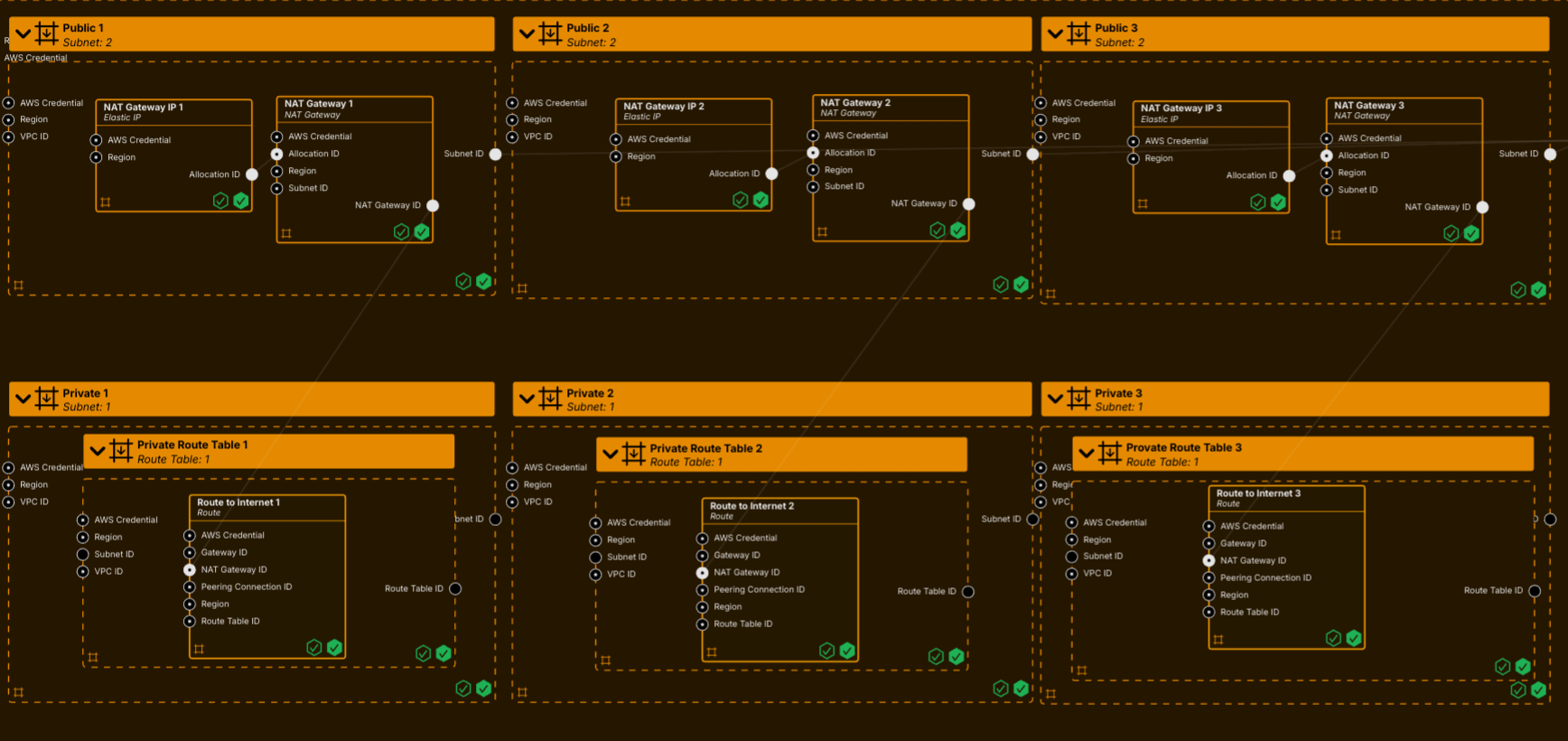
If you have ever had to grapple with a 3,000 line Helm chart to deploy your observability infrastructure, you may be forgiven for thinking that there must be a better way to do this. Whilst YAML has a certain formal elegance, its syntax struggles to express the architectures and relationships embedded in highly complex systems.
Whilst Pulumi have tackled this problem by enabling the use of high level programming languages for IaC, System Initiative are taking a fundamentally more radical approach. Their goal is nothing other than completely reinventing IaC from the ground up. The blog article for the launch of the product is an incredibly ambitious statement of intent. The terms ‘game changer’ and ‘paradigm shift’ tend to be thrown around somewhat casually, this might be a case where their usage is appropriate.
So, what are they proposing? Well, System Initiative is IaC without the code. It is a kind of digital canvas where you manipulate digital twins of your systems. Is the future here or is this the Platform Engineering equivalent of science fiction? Read the article and decide for yourself!