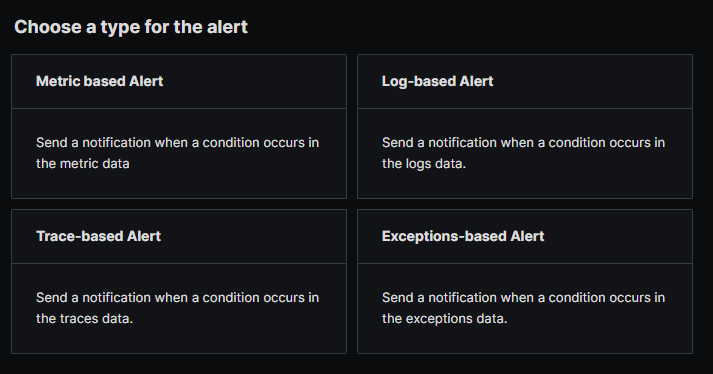
One advantage of running SigNoz in self-hosted mode is that we have access to the ClickHouse backend database. This means that we can explore our telemetry using SQL queries.
The ClickHouse database will be running on a pod in our cluster, so the first thing we will need to do is connect to the ClickHouse client on the ClickHouse pod:
kubectl -n signoz exec -i --tty pod/chi-signoz-clickhouse-cluster-0-0-0 -- bash
Then in the bash session we run a very simple command to kick off the ClickHouse Client:
clickhouse client
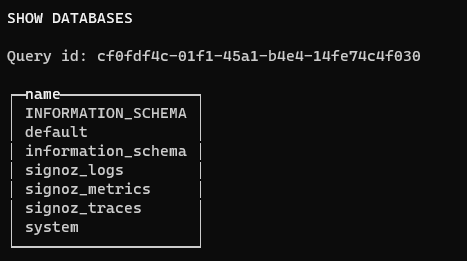
Now we can start exploring the backend databases that store our telemetry. This is a great advantage of running our own self-hosted instance.First of all we will list our databases:
SHOW DATABASES;
The output from the SHOW DATABASES command will be something like this:
Click on image to enlarge
We are quite interested take a look around the signoz_logs database - so we will set that as our database context:
USE signoz_logs
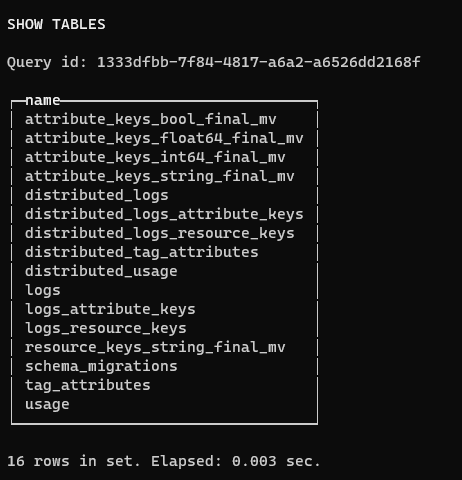
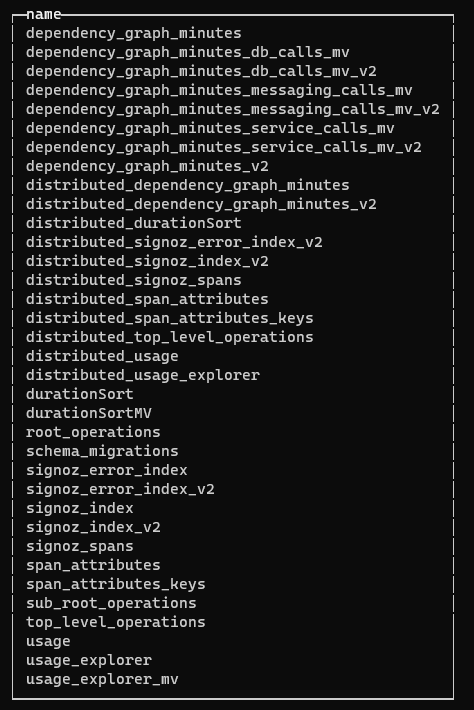
We can now delve into the tables in the signoz_logs database:
SHOW TABLES;
Click on image to enlarge
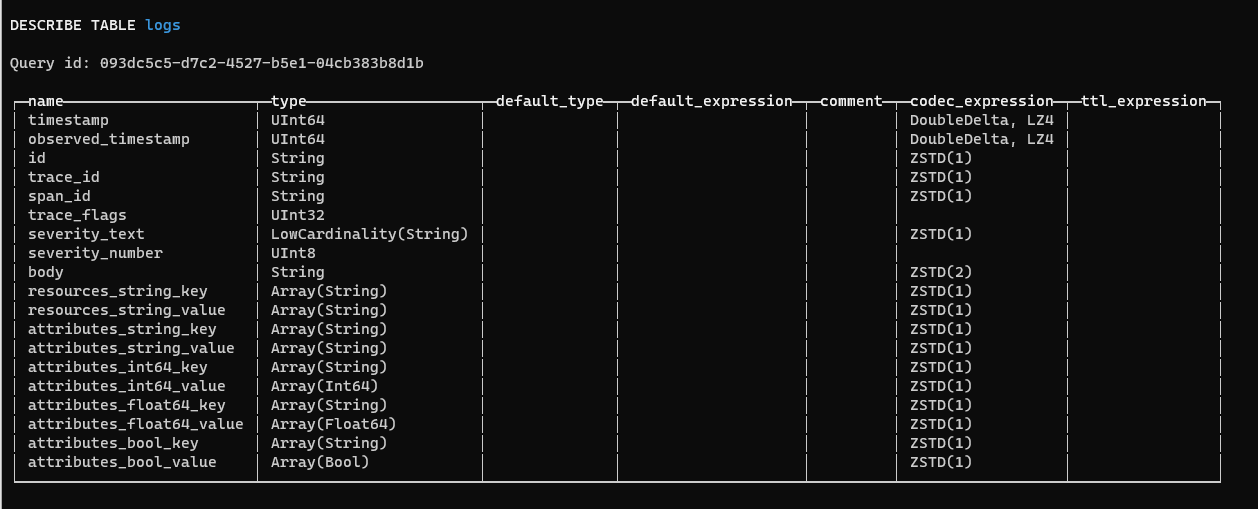
We are really keen to have a look at the structure of the logs table. To do this we just use the DESCRIBE command:
DESCRIBE TABLE logs;
This is our output
Click on image to enlarge
This gives us some really fascinating insights into the internals of a ClickHouse database. As you can see, although we can query the database by using SQL commands, the actual data types are different to the standard ANSI SQL datatypes.
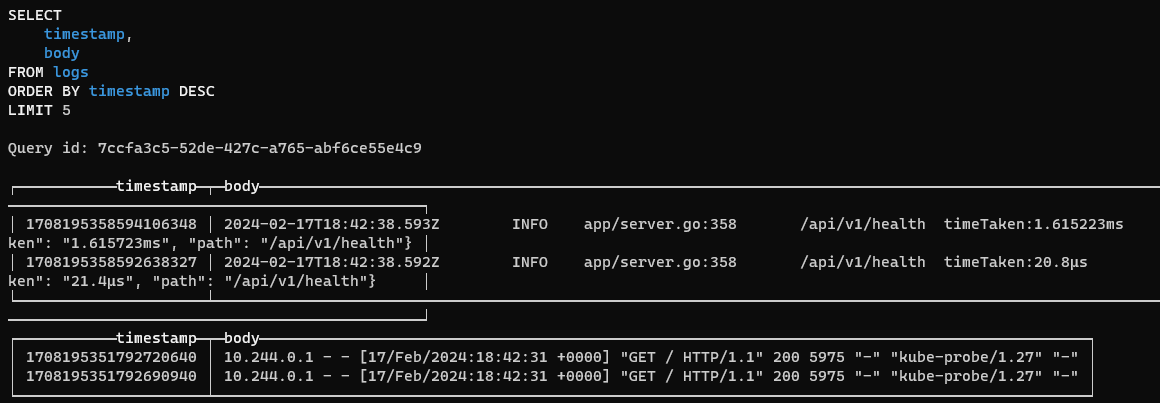
Now we are going to run a simple SELECT query to look at some log data:
SELECT
timestamp,
body
FROM logs
ORDER BY timestamp DESC
LIMIT 5
And the output looks like this:
Click on image to enlarge
This gives us fantastic power and flexibility in querying our logs. Next, let's have a look at the structure of our Trace data:
USE signoz_traces
Once again, if we run the SHOW TABLES; command, we will get a listing.
Click on image to enlarge
We are really interested to see how a span is represented, so lefts find out a bit more about the table:
DESCRIBE TABLE signoz_spans;
Interestingly, there are just three columns.
Click on image to enlarge
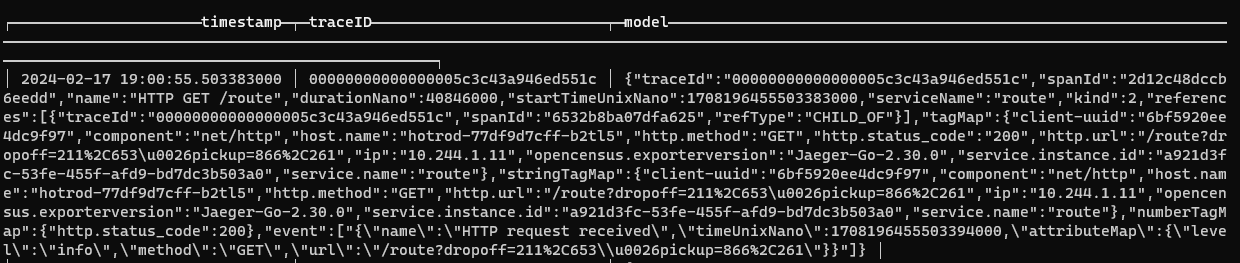
It will be interesting to see what the model column looks like. Let us see some raw data:
SELECT * FROM signoz_spans ORDER BY timestamp DESC LIMIT 5;
As you can see, the model column contains a payload of interesting data:
Click on image to enlarge
For us, being able to dig around in your telemetry like this is not just fascinating, it is also simplifies querying, troubleshooting and maintenance.